
The aim of the talk was to:
- provide a beginner-friendly introductory overview of GANs
- demystify how they work, avoiding unnecessary maths and jargon
- explain the basic of PyTorch, a python machine learning framework
- provide practical tutorial code to explore
- share some of the current heuristics used to make GANs work
The slides for the talk are here: (pdf).
A video recording of the talk is here: (link).
Four-Part Blog
The journey of learning about GANS and writing simple examples is detailed in this 4-part series published on my other blog. This talk is the result of much of the learning and content created during that journey.- Part 1 introduces the idea of adversarial learning and starts to build the machinery of a GAN implementation.
- Part 2 extends the code to learn a simple 1-dimensional pattern 1010.
- Part 3 develops our code to learn to generate 2-dimensional grey-scale images that look like handwritten digits
- Part 4 further develops our code to generate 2-dimensional full-colour images of faces, and also develops a GAN based on convolution layers to learn localised features.
I won't repeat the content of those blogs here - you should read those for a fuller yet gentle journey from preparatory basics through to a working convolutional GAN.
Here I'll set out the key steps taken in the talk.
GANs? Adversarial Learning?
We started by playing a game which challenges us to see if we can tell real photos from computer generated faces apart.
The computer generated images are surprisingly realistic and it was genuinely difficult to tell them apart. See for your self at http://www.whichfaceisreal.com/
These images are generated by GANs, and the game demonstrates their effectiveness.
We also talked about the growing interest in creating art with GANs. A key milestone in the history of art is the sale of a Portrait of Edmond Belamy at Christies for $432,500 in October 2018.

That portrait was generated entirely by computer, using a GAN.
Robbie Barrat, who created the code behind that portrait, himself has some stunning images created by GANs. This is one notable example:

Before diving into GANs, we refreshed our understanding of basic machine learning and how neural networks work.

In essence, neural networks are trained by feeding them data, images for example, and comparing their actual output to the known-good output. This difference, the error, is used to adjust the link weights inside the network with the aim of producing a slightly better output.
Neural networks can be trained to perform tasks like classifying images - and a common tutorial example is to learn to classify images of human handwritten digits, known as the MNIST dataset.
Make Your Own Neural Network is an accessible introduction to neural networks designed for beginners which starts from scratch and builds a simple neural network to classify these digits.

We proceeded to learn about PyTorch, a python framework which makes doing machine learning easier. In particular it provides automatic gradient calculation, which is a critical part of updating a neural network. Previously the algebra and calculus had to be done by hand, but today toolkits like PyTorch can do this automatically for many kinds of networks we might want to build.
A working notebook showing this capability was demonstrated, using Google's colab service:
PyTorch also makes using a GPU to accelerate machine learning very easy. Again a simple live notebook was demonstrated to show the key code elements:
Using the GPU does have some overhead which means for small tasks the benefit isn't there, but as the following graph shows, the benefits emerge as we scale the data or size of neural network we're training:
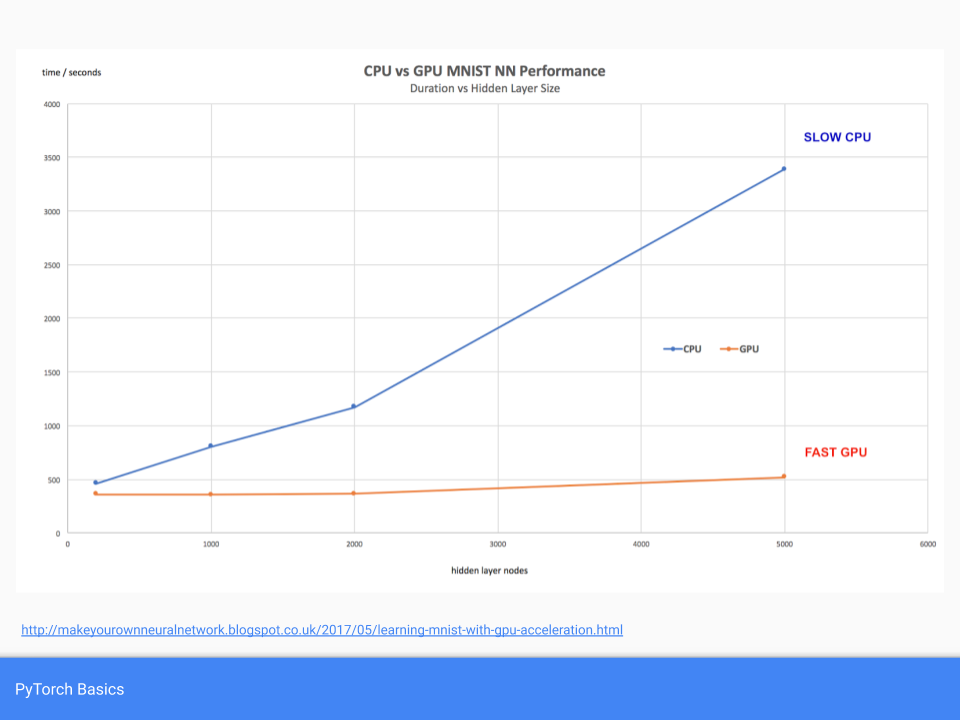
A simple example of PyTorch code to classify the MNIST images was explored.
Using this simple example, we focussed on the machinery of PyTorch code - subclassing from the nn.Module class, building up network layers, choosing a loss function and an optimiser for performing the network updates.

This code pattern will remain pretty much the same as our code grows, so is a good educational example.
We finally asked what a GAN was.
We started by looking at the architecture of simple machine learning. A machine learning model, which can be a neural network but doesn't have to be, has its internal parameters adjusted in response to the error it produces:

We then looked at the GAN architecture:

We have a learning model, a discriminator, which it is trained to separate real data from fake data. On its own that's just like a typical machine learning system. We also have a second machine learning model, a generator, which learns to generate data with the aim of getting it past the discriminator.
If this architecture works well, the discriminator and the generator compete to out-do each other.
As the discriminator gets better and better at telling real from fake data apart, the generator also gets better and better at generated fake data that can pass as real.
A common analogy is of a forger learning to get better at fooling a policeman or detective:

This adversarial dynamic is quite unique and in fact a relatively recent invention (Ian Goodfellow, 2014), and is the reason the architecture is called a generative adversarial network.
We then proceeded in steps to develop our GAN code. We started first with a simple example learning a 1-dimensional 1010 pattern:
The simplicity of the task allowed us to focus on the machinery again, especially the collection and display of the error, often called the loss.

Normally the loss is expected to fall to zero in a normal network, but with a GAN the discriminator should find it harder and harder to tell apart the real data from the generated data - and so the error should approach 1/2 (or 1/4 if we're using mean squared error as in the picture above).
The following shows visually how the output of the generator improves as training progresses. You can clearly see the 1010 pattern emerge.

The next step was to learn 2-dimensional data, images, and the monochrome MNIST dataset is ideal:
The shape and nature of the discriminator followed the simple classifier we developed earlier - a simple network with one middle layer. The input size is fixed at 784 because the images are 28x28. The output size is 10 to match the 10 digits.

The generator is often designed first as a mirror of the discriminator, and then adjusted as required.
The results looked disappointing:

The generator has failed to learn to draw digits, and all the images look very similar.
We discussed how, in general, GANs are hard to train, with common pitfalls like mode collapse where only one of many possible solutions is found by the generator.

It is worth remembering that a successful GAN is a fine equilibrium between the generator and the discriminator.
The next version of the code implemented some common improvements - using a leakyRELU activation instead of the vanilla sigmoid because it doesn't suffer from vanishing gradients, layer normalisation to rescale network signals to the sweet spot for the activation functions, and a stronger Adam optimiser which works per-learning parameter.
The results looked much better:

Those generated images are impressive if we remember that the generator has not seen the real images from the data set at all. We've also avoided mode collapse too.
We then moved beyond the monochrome images to full-colour photos of celebrity faces, using a popular CelebA dataset of 200,000 images. For our experiments, we used only 20,000.

The code itself didn't need any structural changes, only needed to adapt to the new 3-channel images and larger but still simple neural networks:

The results were impressive in that a diverse set of faces were indeed generated:

There are faces with different skin colour, different hair styles, and even different pose orientations too.
It is wort noting that the GAN approach doesn't learn "average faces". What is learned is a probability distribution from which samples can pass the discriminator. This is why the generated images are nicely diverse.
A second round, epoch, of training improves the images:

And more training improves the images again:

Much further training led to a degradation of image quality, which suggests we've reached the limits of our intentionally simple architecture.
The animated image at the top of this post shows several generated images being interpolated smoothly. They are generated by moving a consecutive sequence of 1's across the 100-long input array.
We next looked at convolutional neural networks. The reason for this is that convolution layers learn localised image features, and are well suited to image classification tasks.
The following diagram shows how a convolution kernel pick out diagonal patterns in the source image and builds a feature map.

We can set a neural network to learn these kernels by itself instead of predefining them. Here is a simple example of an MNIST classifier that uses convolution layers:
For a GAN, we hope that a convolution layers in the generator will learn to build an image from features, perhaps elements like eyes, noses, lips etc.
At first the results from the generator were not as expected, reflecting the difficulty of designing and training a GAN:

That GAN was rather good at generating horror characters!
After some trial and error, a successful and still simple GAN was found:
- https://github.com/makeyourownalgorithmicart/makeyourownalgorithmicart/blob/master/blog/generative-adversarial-network/04_celeba_gan_conv.ipynb
The results were impressive. The following from one training epoch shows how the faces are indeed being patched together from learned features.

A second epoch improves how the faces are constructed.

Six epochs again shows some improvement.

Eight epochs results in faces that are starting to be constructed more smoothy.

The following is an animation of several generated faces smoothly transitioned just for effect.

Although these images might not win awards for fidelity, they do show that even a very simple network using only a few lines of code can still create fascinating images.
They're fascinating because the generator has never seen the real images, and has still learned to construct faces from features it has also learned indirectly via the discriminator.
Conclusion
I was really pleased the talk matched the audience's expectations of an introductory talk that demystified GANs, and also provided simple tutorial code and summarised a few of the heuristics currently used to make them work.
No comments:
Post a Comment