We were also lucky to have Brod Ross, an artist from Falmouth, who shared his work and process creating stunning 3d scenes based on fractal constructions.

The slides are online: pdf.
Organic Patterns
We started by taking a look at examples of patterns that looked organic and natural but were in fact created by a mathematical process.Here is an example that has very fine filament-like details, combining a feeling of detailed thread work or the growth of an exotic plant.

The following is another example that looks like an underwater scene of seahorse-like creatures.

These patterns are entirely generated by a mathematical process. This surprises many as they're very organic and natural in form.
The previous two patterns are details from the famous Mandelbrot fractal. The following are examples of a related mathematical pattern called a Julia fractal.

These are more self-contained and a higher degree of symmetry.

These patterns are fractals - they are self-similar at different scales.
These fractals are named after the key characters who either discovered them, or did much of the ground-breaking work in the mathematical processes that create them - Benoit Mandelbrot and Gaston Julia.

Simple Maths
We then took our first gentle steps into mathematics to prepare ourselves for the ideas that lie behind these fractals.The following expression x2 + c is rather simple. All it says is "square a number and add another number to it". Square means "multiply by itself".

For example, if x is 2 and c is 3, then x2+ c is 4 + 3 = 7.
Easy enough.
Yet surprisingly, this is the formula at the heart of the Mandelbrot and Julia fractals.
The stark contrast between the simplicity of this formula and the extremely detailed organic fractals we've seen is a perfect example of how mathematics has a beauty, hidden not too far under its surface!
Let's take another step.
The way this simple formula is used, is to take the answers it gives us and feed them back in again. The following picture explains this idea better.

So if x started at 2, and c is 3, we've seen the result is 7. Let's put that back in. So 72 + 3 = 52.
We can think of x2 + c as a machine that we feed, and that spits out an answer.
Let's look at a simpler example using a simpler machine:

This machine is simply x2. If we start feeding it 2, it spits out 4. If we feed that 4 back in again, it spits out 16. The sequence of numbers being spat out grows larger and larger through 256, 65536, and 4294967296 and upwards.
What happens if we start with not 2 but 0.5. The numbers seem to get smaller and smaller.
The starting number seems to decide whether the numbers get bigger or smaller.

Let's make a map of how numbers behave - a map showing whether numbers get bigger and bigger, or smaller and smaller.
The following shows the number 2 coloured green, because iterated through the x2 machine it gets bigger and bigger.

The next picture shows the number 0.5 coloured red, because iterated through the machine the numbers get smaller and smaller.

If we continue to test lots of numbers on the number line, including negative numbers we get a map that looks like this:

The negative numbers smaller than -1 are green because they do get bigger and bigger. Negative numbers squared become positive. The red region is around 0 and that makes sense because fractions less than 1 get smaller and smaller.
The map also shows 1 and -1 coloured blue because those numbers, when iterated through x2, don't get bigger or smaller, they stay at 1. The blue dots mark the boundary between the red and green territories.
So far, the maths has been easy. Let's take one more step.
Let's keep the idea of feeding a machine like we have before. Let's keep the idea of drawing a map to show how starting numbers behave.
But let's change the numbers to another kind of number called a complex number, even though they aren't complex at all!
Complex Numbers
Complex numbers aren't complex. They are just a composite number made of two normal numbers.
One part is called the real part, and the other is called the imaginary part. We mustn't let this surreal naming scare us away!
Things made of 2 parts or 2 numbers aren't unfamiliar. We're used to latitude and longitude on geographical maps, chess board positions or cells in a spreadsheet.

Because complex numbers have 2 parts, we can visualise them on a 2d surface like a grid or a map. It is normal for the real part to be along the horizontal direction, and the imaginary part along the vertical direction.
If we want to push these numbers through our machine, we need to know how to add and multiply them.
Adding complex numbers is easy - we just combine real parts with real parts, and imaginary parts with imaginary parts:

Multiplying is also simple in principle. We combine all the elements just like we might multiply out brackets at school algebra:

We can sweep together real parts and imaginary parts but we're left with an element with i2. In the above example it is 3i * 5i = 15i2.
What is i2? Let's look at the following picture showing what happens when 1 is multiplied by i. The result is a rotation of 90 degrees anticlockwise.

Another multiplication by i means another similar rotation which leads to -1.
So i2 = -1.
We can now finish our multiplication:

So now we know how to add and multiply complex numbers, we're ready to feed these numbers to a machine again.

We'll start x at 0 + 0i which is the complex number for 0. We can choose a complex number for c, we just need to stick with it consistently through all the calculations.
Because complex numbers are 2 dimensional, the map we draw to show how they behave as we iterate them through the x2 + c function will be 2 dimensional too.

Surprising Behaviour of Complex Numbers
Let's see what happens is we start with x = 0 + 0i and c = 2 + 2i.
We can see the complex numbers get bigger rand bigger. The second value is 2 + 2i, the third is 2 + 10i, and the fourth is -94 + 42i. On the graph we can see the numbers are spiralling outwards.
The following picture shows this spiralling out, and also the direct distance to the point - the magnitude of the complex number. We can see the magnitude gets bigger quickly.

Let's try c = 0.4 + 0.4i.

This time we can see the numbers spiralling around before finally escaping. The magnitude chart shows this eventual explosion. This is interesting behaviour given how simple the function x2 + c is.
Let's try c = -0.3 + 0.4i.

The numbers seem to be getting sucked into an orbit around a specific point, and getting sucked inwards to that point - like a black hole. That point, in mathematical terms, is called an attractor.
More interesting behaviour!
Let's try c = 0.3 + 0.5i.

This time the orbit is more sustained and has a larger shape. Another kind of behaviour - all from the innocent looking x2 + c.
What could a map of this behaviour look like?
The following shows an early plot created in 1978!

The map isn't a circle or a square, an oval or a diamond. It is a strange beetle shape!
Again - this strangeness from the innocent x2 + c function!
Here is a higher-resolution plot of the map, showing which numbers explode and which fall towards zero.

Finally ... the famous Mandelbrot Set.
We can see self-similarity in the pattern. There are smaller bulbs on the main bulbs, and each one of those has smaller bulbs too.
Let's remind ourselves how the image is created:

We pick a point on the 2-d map to test. We push that number as c through the function x2 + c, repeatedly feeding the answer back into the function. If the numbers get larger and larger we colour the point white. If the numbers fall towards zero, we colour them black.
We saw earlier that sometimes the numbers seem to orbit around a point, not exploding or diminishing. These are at the boundary of that beetle, dividing the two kinds of regions.
The most popular renditions of the Mandelbrot fractal are coloured. There are many options for choosing how to colour the fractal, but the following is a popular option:

We still colour black the regions that fall towards zero. For the regions that explode, we identify how fast the numbers grow and use this rate to choose a colour.

When calculating the numbers, we can stop if the magnitude get's larger than 2. There is a mathematical proof that shows that if a number get's larger than 2, then it will escape.

We also set a maximum for the number of times we iterate the function because we don't have all the time in the world to see if a point diverges or converges. If the size reaches 2 before this maximum is reached, we can use the actual iteration count as a measure of how fast the number escapes, which we can use for the colouring.
The fractal is infinitely detailed, and we can set the "window" size to see the detail more closely.

That simple zooming-in reveals an incredible amount of beautiful detail - all from that very simple function!
The following youtube video shows an animated zooming into the Mandelbrot fractal ... the level of detail is breathtaking!
You can find commented Python code to draw a Mandelbrot set here:
Julia Sets
The Julia fractals are created in an almost identical manner. There is only one change:
With the Mandelbrot fractal, we start z as 0 + 0i and c as the point being tested.
With the Julia fractal we set z to start as the point being tested, but set c to a constant all over the map.
In effect, the roles of z and c are swapped.
Here is another nice example of a Julia set.

Sample Python code for creating a Julia set is here:
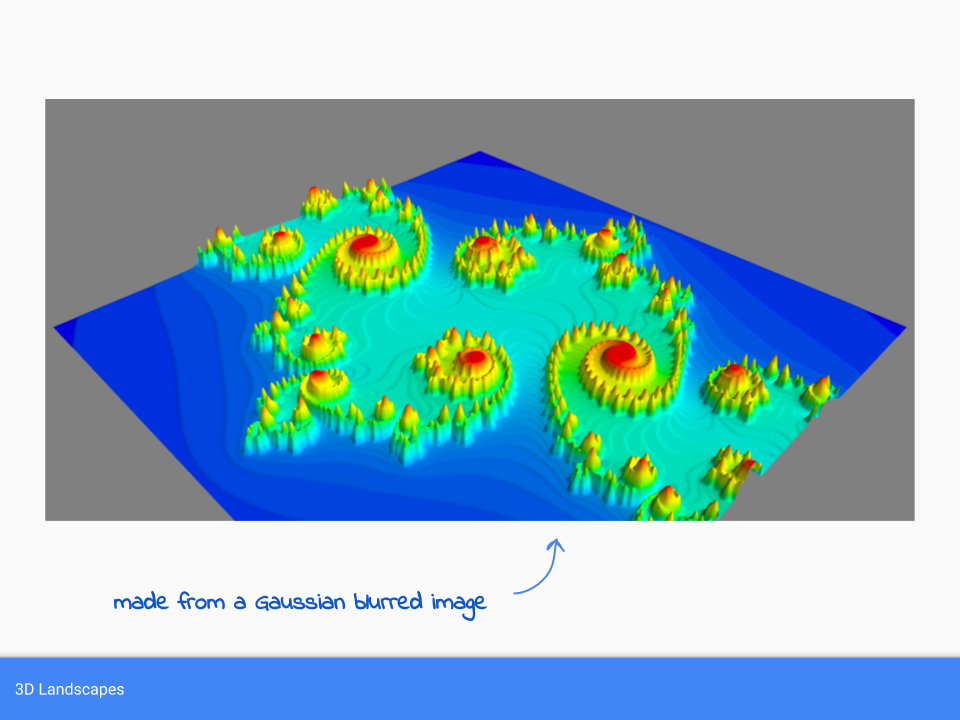
3D Landscapes
We previously used the rate of escape to choose a colour. We can also use this rate as a height of a point on a 3d landscape.Here is the simple Mandelbrot fractal transformed into a 3d landscape surface.

A closer zoom into a Julia fractal creates a more interesting landscape:
Being able to interactively move around and explorable a landscape is an interesting experience:

The code for creating and exploring landscapes like this is online too:
Mandelbulb Worlds
We were lucky to have Brod Ross show some of the worlds he creates using tools which create an almost photorealistic rendering of scenes containing objects that are fractals creates in basically the same way as the Mandelbrot and Julia sets.
Here are some of his works:



If you look closely, you can see the fractal nature of the structures.
Tools
If you want to use tools to explore these fractals, the following are good starting points:- A web-only Mandelbrot explorer, no need to install any software: http://www.mandelbulb.com/2014/mandelbulb-3d-mb3d-fractal-rendering-software/
- A fast open source renderer, so fast it can animate a zoom in real time: http://matek.hu/xaos/doku.php
- MandelBulb 3D for creating scenes similar to Brod's work above: http://www.mandelbulb.com/